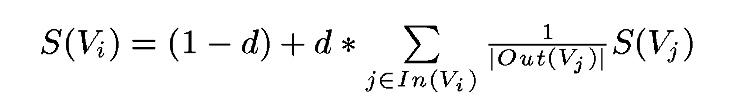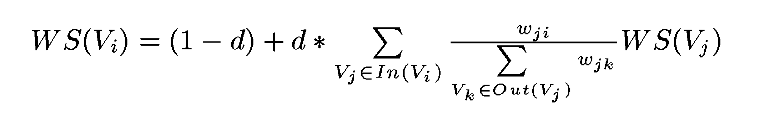1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
| import java.util.*;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.util.CharArraySet;
import org.apache.lucene.util.Version;
/*
* javac -cp '.:lucene-core-4.10.1.jar:lucene-analyzers-common-4.10.1.jar:lucene-analyzers-smartcn-4.10.1.jar' TextRankKeyword.java
*
* java -cp '.:lucene-core-4.10.1.jar:lucene-analyzers-common-4.10.1.jar:lucene-analyzers-smartcn-4.10.1.jar' TextRankKeyword `cat a.txt` 50|grep -E '.{2,} - '
*
*/
/**
* 基于TextRank算法的关键字提取,适用于单文档
* @author hankcs
* @modify wuwenjie
*/
public class TextRankKeyword {
/**
* 提取多少个关键字
*/
int nKeyword = 10;
/**
* 阻尼系数(DampingFactor),一般取值为0.85
*/
final static float d = 0.85f;
/**
* 最大迭代次数
*/
final static int max_iter = 200;
final static float min_diff = 0.001f;
/**
* 提取关键词
* @param document 文档内容
* @param size 希望提取几个关键词
* @return 一个列表
*/
public static List<String> getKeywordList(String document, int size)
throws Exception{
TextRankKeyword textRankKeyword = new TextRankKeyword();
textRankKeyword.nKeyword = size;
return textRankKeyword.getKeyword(document);
}
/**
* 提取关键词
* @param content
* @return
*/
public List<String> getKeyword(String content) throws Exception{
Set<Map.Entry<String, Float>> entrySet = getTermAndRank(content, nKeyword).entrySet();
List<String> result = new ArrayList<String>(entrySet.size());
for (Map.Entry<String, Float> entry : entrySet)
{
result.add(entry.getKey());
}
return result;
}
/**
* 返回全部分词结果和对应的rank
* @param content
* @return
*/
public Map<String,Float> getTermAndRank(String content) throws Exception{
assert content != null;
CharArraySet cas = new CharArraySet(0, true);
// 自定义停用词
String[] self_stop_words = { "的", "在","了", "呢", ",", ":", ",","是","一","我","会","这","着","也","为","里","个","要","来","与","但","只","对","就","那些","这些","她们","我们","他们","但是","或者","一个","其他","自己","人","和","上","不","有","他"};
for (int i = 0; i < self_stop_words.length; i++) {
cas.add(self_stop_words[i]);
}
// 加入系统默认停用词
Iterator<Object> itor = SmartChineseAnalyzer.getDefaultStopSet().iterator();
while (itor.hasNext()) {
cas.add(itor.next());
}
// 中英文混合分词器(其他几个分词器对中文的分析都不行)
SmartChineseAnalyzer sca = new SmartChineseAnalyzer(cas);
List<String> wordList = new LinkedList<String>();
TokenStream ts = sca.tokenStream("field", content);
CharTermAttribute ch = ts.addAttribute(CharTermAttribute.class);
ts.reset();
while (ts.incrementToken()) {
wordList.add(ch.toString());
//System.out.print(ch.toString()+"\\");
}
ts.end();
ts.close();
return getRank(wordList);
}
/**
* 返回分数最高的前size个分词结果和对应的rank
* @param content
* @param size
* @return
*/
public Map<String,Float> getTermAndRank(String content, Integer size)throws Exception{
Map<String, Float> map = getTermAndRank(content);
Map<String, Float> result = new LinkedHashMap<String, Float>();
for (Map.Entry<String, Float> entry : new MaxHeap<Map.Entry<String, Float>>(size, new Comparator<Map.Entry<String, Float>>()
{
@Override
public int compare(Map.Entry<String, Float> o1, Map.Entry<String, Float> o2)
{
return o1.getValue().compareTo(o2.getValue());
}
}).addAll(map.entrySet()).toList())
{
result.put(entry.getKey(), entry.getValue());
}
return result;
}
/**
* 使用已经分好的词来计算rank
* @param termList
* @return
*/
public Map<String,Float> getRank(List<String> wordList)
{
// System.out.println(wordList);
Map<String, Set<String>> words = new TreeMap<String, Set<String>>();
Queue<String> que = new LinkedList<String>();
for (String w : wordList)
{
if (!words.containsKey(w))
{
words.put(w, new TreeSet<String>());
}
que.offer(w);
if (que.size() > 5)
{
que.poll();
}
for (String w1 : que)
{
for (String w2 : que)
{
if (w1.equals(w2))
{
continue;
}
words.get(w1).add(w2);
words.get(w2).add(w1);
}
}
}
// System.out.println(words);
Map<String, Float> score = new HashMap<String, Float>();
for (int i = 0; i < max_iter; ++i)
{
Map<String, Float> m = new HashMap<String, Float>();
float max_diff = 0;
for (Map.Entry<String, Set<String>> entry : words.entrySet())
{
String key = entry.getKey();
Set<String> value = entry.getValue();
m.put(key, 1 - d);
for (String element : value)
{
int size = words.get(element).size();
if (key.equals(element) || size == 0) continue;
m.put(key, m.get(key) + d / size * (score.get(element) == null ? 0 : score.get(element)));
}
max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));
}
score = m;
if (max_diff <= min_diff) break;
}
return score;
}
public static void main(String[] args) throws Exception{
TextRankKeyword myout = new TextRankKeyword();
Map<String,Float> myRank = myout.getTermAndRank(args[0], Integer.parseInt(args[1]));
for(String key: myRank.keySet())
System.out.println(key + " - " + myRank.get(key));
}
}
|