1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| # 初始化数据
m <- rbind(
matrix(rnorm(100, sd = 0.6), ncol = 2), # 标准正态分布
matrix(rnorm(100, mean = 2, sd = 0.6), ncol = 2),
matrix(rnorm(100, mean = 4, sd = 0.6), ncol = 2),
matrix(rnorm(50, mean = -3, sd = 0.6), ncol = 2)
)
colnames(m) <- c("x", "y")
m <- apply(m,2,scale) # 标准化
cl <- kmeans(m, 4) # 使用Kmeans进行聚类分析
cl
cl$size # 聚类每个分组的数量
cl$totss # The total sum of squares.
cl$withinss # Vector of within-cluster sum of squares
cl$centers # 聚类中心
1-(cl$tot.withinss/cl$totss) #1-(sum(cl$withinss)/cl$totss)
############################
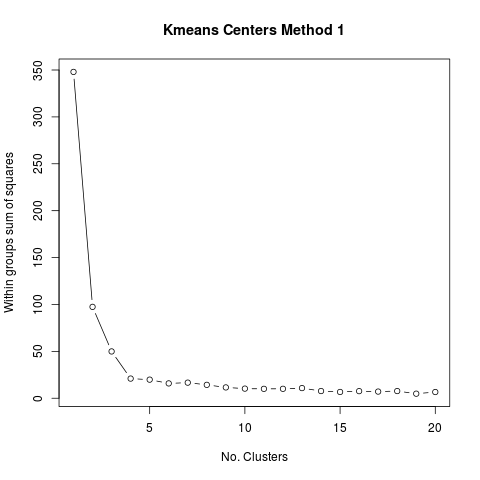
# K-means 确定组数1
png("Kmeans_group_1.png") # 输出图像到png文件
wss <- (nrow(m)-1)*sum(apply(m,2,var))
for(i in 2:20)
wss[i] <- sum(kmeans(m,centers=i)$withinss)
plot(1:20,wss,type="b",xlab="No. Clusters",
ylab="Within groups sum of squares",
main="Kmeans Centers Method 1")
identify(wss)
dev.off()
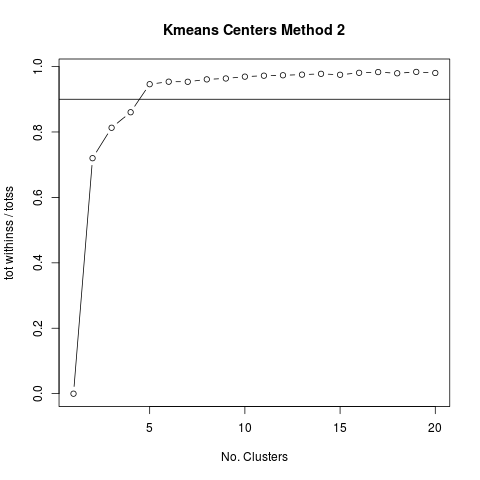
# K-means 确定组数2
png("Kmeans_group_2.png")
wt <- c()
for(i in 1:20){
ks <- kmeans(m,centers=i)
wt[i] <- (1 - (ks$tot.withinss / ks$totss))
}
plot(1:20,wt,type="b",xlab="No. Clusters",
ylab="tot withinss / totss",
main="Kmeans Centers Method 2")
abline(h=0.9);identify(wt)
dev.off()
############################
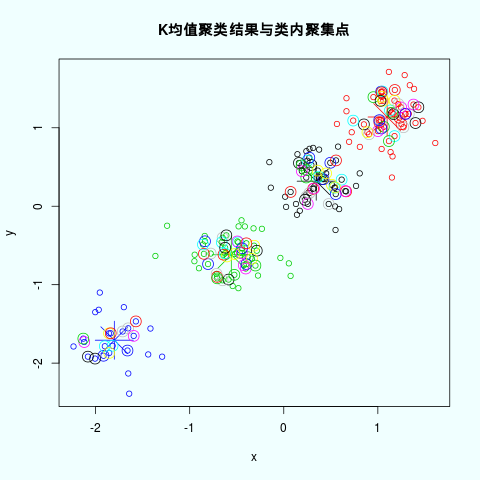
# 找出内部点
resid.m <- m - fitted(cl)
# 计算 样本与对应中心点的差
# cluster centers "fitted" to each obs.
## 计算距离
distance <- function(x){sqrt(x[1]^2+x[2]^2)}
dis <- apply(resid.m,1,distance)
# 将距离与样本整合在一起
m <- as.data.frame(cbind(m,cl$cluster,dis))
colnames(m) <- c("x", "y","cluster","dis")
inpoint <- c()
# 筛选出每个类中内部的样本 小于1.2倍的类内平均距离
for (i in 1:length(cl$size)){
# print(i)
tm <- m[which(m$cluster == i),]
means <- mean(tm$dis) #每群的平均距离
tpoint <- tm[which(tm$dis <= 1.2*means),]
# <每群的平均距离,在类内部
inpoint <- rbind(inpoint,tpoint)
}
inpoint <- inpoint[,c("x","y")]
m <- m[,c("x","y")]
png("Kmeans_inside.png")
# 设置背景颜色
par(bg = "azure")
# 画出聚类样本
plot(m,col = cl$cluster,main="K均值聚类结果与类内聚集点")
# 画出样本中心
points(cl$centers, col = 1:length(cl$size), pch = 8, cex = 5)
# 画出内部点
points(inpoint, col = 1:nrow(inpoint), pch = 1, cex = 2)
dev.off()
|